Euclidean Cluster Extraction
In this tutorial we will learn how to extract Euclidean clusters with the
pcl::EuclideanClusterExtraction class. In order to not complicate the
tutorial, certain elements of it such as the plane segmentation algorithm,
will not be explained here. Please check the Plane model segmentation
tutorial for more information.
Theoretical Primer
A clustering method needs to divide an unorganized point cloud model 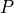 into smaller parts so that the overall processing time for is
significantly reduced. A simple data clustering approach in an Euclidean sense
can be implemented by making use of a 3D grid subdivision of the space using
fixed-width boxes, or more generally, an octree data structure. This particular
representation is very fast to build and is useful for situations where either
a volumetric representation of the occupied space is needed, or the data in
each resultant 3D box (or octree leaf) can be approximated with a different
structure. In a more general sense however, we can make use of nearest
neighbors and implement a clustering technique that is essentially similar to a
flood fill algorithm.
into smaller parts so that the overall processing time for is
significantly reduced. A simple data clustering approach in an Euclidean sense
can be implemented by making use of a 3D grid subdivision of the space using
fixed-width boxes, or more generally, an octree data structure. This particular
representation is very fast to build and is useful for situations where either
a volumetric representation of the occupied space is needed, or the data in
each resultant 3D box (or octree leaf) can be approximated with a different
structure. In a more general sense however, we can make use of nearest
neighbors and implement a clustering technique that is essentially similar to a
flood fill algorithm.
Let’s assume we are given a point cloud with a table and objects on top of it. We want to find and segment the individual object point clusters lying on the plane. Assuming that we use a Kd-tree structure for finding the nearest neighbors, the algorithmic steps for that would be (from [RusuDissertation]):
create a Kd-tree representation for the input point cloud dataset
set up an empty list of clusters
, and a queue of the points that need to be checked
;
then for every point
, perform the following steps:
add
to the current queue
for every point
do:
search for the set
of point neighbors of
;
for every neighbor
, check if the point has already been processed, and if not add it to
when the list of all points in
the algorithm terminates when all points
The Code
First, download the dataset table_scene_lms400.pcd and save it somewhere to disk.
Then, create a file, let’s say, cluster_extraction.cpp in your favorite
editor, and place the following inside it:
1#include <pcl/ModelCoefficients.h>
2#include <pcl/point_types.h>
3#include <pcl/io/pcd_io.h>
4#include <pcl/filters/extract_indices.h>
5#include <pcl/filters/voxel_grid.h>
6#include <pcl/features/normal_3d.h>
7#include <pcl/search/kdtree.h>
8#include <pcl/sample_consensus/method_types.h>
9#include <pcl/sample_consensus/model_types.h>
10#include <pcl/segmentation/sac_segmentation.h>
11#include <pcl/segmentation/extract_clusters.h>
12#include <iomanip> // for setw, setfill
13
14int
15main ()
16{
17 // Read in the cloud data
18 pcl::PCDReader reader;
19 pcl::PointCloud<pcl::PointXYZ>::Ptr cloud (new pcl::PointCloud<pcl::PointXYZ>), cloud_f (new pcl::PointCloud<pcl::PointXYZ>);
20 reader.read ("table_scene_lms400.pcd", *cloud);
21 std::cout << "PointCloud before filtering has: " << cloud->size () << " data points." << std::endl; //*
22
23 // Create the filtering object: downsample the dataset using a leaf size of 1cm
24 pcl::VoxelGrid<pcl::PointXYZ> vg;
25 pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_filtered (new pcl::PointCloud<pcl::PointXYZ>);
26 vg.setInputCloud (cloud);
27 vg.setLeafSize (0.01f, 0.01f, 0.01f);
28 vg.filter (*cloud_filtered);
29 std::cout << "PointCloud after filtering has: " << cloud_filtered->size () << " data points." << std::endl; //*
30
31 // Create the segmentation object for the planar model and set all the parameters
32 pcl::SACSegmentation<pcl::PointXYZ> seg;
33 pcl::PointIndices::Ptr inliers (new pcl::PointIndices);
34 pcl::ModelCoefficients::Ptr coefficients (new pcl::ModelCoefficients);
35 pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_plane (new pcl::PointCloud<pcl::PointXYZ> ());
36 pcl::PCDWriter writer;
37 seg.setOptimizeCoefficients (true);
38 seg.setModelType (pcl::SACMODEL_PLANE);
39 seg.setMethodType (pcl::SAC_RANSAC);
40 seg.setMaxIterations (100);
41 seg.setDistanceThreshold (0.02);
42
43 int nr_points = (int) cloud_filtered->size ();
44 while (cloud_filtered->size () > 0.3 * nr_points)
45 {
46 // Segment the largest planar component from the remaining cloud
47 seg.setInputCloud (cloud_filtered);
48 seg.segment (*inliers, *coefficients);
49 if (inliers->indices.size () == 0)
50 {
51 std::cout << "Could not estimate a planar model for the given dataset." << std::endl;
52 break;
53 }
54
55 // Extract the planar inliers from the input cloud
56 pcl::ExtractIndices<pcl::PointXYZ> extract;
57 extract.setInputCloud (cloud_filtered);
58 extract.setIndices (inliers);
59 extract.setNegative (false);
60
61 // Get the points associated with the planar surface
62 extract.filter (*cloud_plane);
63 std::cout << "PointCloud representing the planar component: " << cloud_plane->size () << " data points." << std::endl;
64
65 // Remove the planar inliers, extract the rest
66 extract.setNegative (true);
67 extract.filter (*cloud_f);
68 *cloud_filtered = *cloud_f;
69 }
70
71 // Creating the KdTree object for the search method of the extraction
72 pcl::search::KdTree<pcl::PointXYZ>::Ptr tree (new pcl::search::KdTree<pcl::PointXYZ>);
73 tree->setInputCloud (cloud_filtered);
74
75 std::vector<pcl::PointIndices> cluster_indices;
76 pcl::EuclideanClusterExtraction<pcl::PointXYZ> ec;
77 ec.setClusterTolerance (0.02); // 2cm
78 ec.setMinClusterSize (100);
79 ec.setMaxClusterSize (25000);
80 ec.setSearchMethod (tree);
81 ec.setInputCloud (cloud_filtered);
82 ec.extract (cluster_indices);
83
84 int j = 0;
85 for (const auto& cluster : cluster_indices)
86 {
87 pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_cluster (new pcl::PointCloud<pcl::PointXYZ>);
88 for (const auto& idx : cluster.indices) {
89 cloud_cluster->push_back((*cloud_filtered)[idx]);
90 } //*
91 cloud_cluster->width = cloud_cluster->size ();
92 cloud_cluster->height = 1;
93 cloud_cluster->is_dense = true;
94
95 std::cout << "PointCloud representing the Cluster: " << cloud_cluster->size () << " data points." << std::endl;
96 std::stringstream ss;
97 ss << std::setw(4) << std::setfill('0') << j;
98 writer.write<pcl::PointXYZ> ("cloud_cluster_" + ss.str () + ".pcd", *cloud_cluster, false); //*
99 j++;
100 }
101
102 return (0);
103}
The Explanation
Now, let’s break down the code piece by piece, skipping the obvious.
// Read in the cloud data
pcl::PCDReader reader;
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud (new pcl::PointCloud<pcl::PointXYZ>), cloud_f (new pcl::PointCloud<pcl::PointXYZ>);
reader.read ("table_scene_lms400.pcd", *cloud);
std::cout << "PointCloud before filtering has: " << cloud->size () << " data points." << std::endl;
.
.
.
while (cloud_filtered->size () > 0.3 * nr_points)
{
.
.
.
// Remove the plane inliers, extract the rest
extract.setNegative (true);
extract.filter (*cloud_f);
cloud_filtered = cloud_f;
}
The code above is already described in other tutorials, so you can read the explanation there (in particular Plane model segmentation and Extracting indices from a PointCloud).
// Creating the KdTree object for the search method of the extraction
pcl::search::KdTree<pcl::PointXYZ>::Ptr tree (new pcl::search::KdTree<pcl::PointXYZ>);
tree->setInputCloud (cloud_filtered);
There we are creating a KdTree object for the search method of our extraction algorithm.
std::vector<pcl::PointIndices> cluster_indices;
Here we are creating a vector of PointIndices, which contain the actual index information in a vector<int>. The indices of each detected cluster are saved here - please take note of the fact that cluster_indices is a vector containing one instance of PointIndices for each detected cluster. So cluster_indices[0] contains all indices of the first cluster in our point cloud.
pcl::EuclideanClusterExtraction<pcl::PointXYZ> ec;
ec.setClusterTolerance (0.02); // 2cm
ec.setMinClusterSize (100);
ec.setMaxClusterSize (25000);
ec.setSearchMethod (tree);
ec.setInputCloud (cloud_filtered);
ec.extract (cluster_indices);
Here we are creating a EuclideanClusterExtraction object with point type PointXYZ since our point cloud is of type PointXYZ. We are also setting the parameters and variables for the extraction. Be careful setting the right value for setClusterTolerance(). If you take a very small value, it can happen that an actual object can be seen as multiple clusters. On the other hand, if you set the value too high, it could happen, that multiple objects are seen as one cluster. So our recommendation is to just test and try out which value suits your dataset.
We impose that the clusters found must have at least setMinClusterSize() points and maximum setMaxClusterSize() points.
Now we extracted the clusters out of our point cloud and saved the indices in cluster_indices. To separate each cluster out of the vector<PointIndices> we have to iterate through cluster_indices, create a new PointCloud for each entry and write all points of the current cluster in the PointCloud.
int j = 0;
for (const auto& cluster : cluster_indices)
{
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_cluster (new pcl::PointCloud<pcl::PointXYZ>);
for (const auto& idx : cluster.indices) {
cloud_cluster->push_back((*cloud_filtered)[idx]);
} //*
cloud_cluster->width = cloud_cluster->size ();
cloud_cluster->height = 1;
cloud_cluster->is_dense = true;
Compiling and running the program
Add the following lines to your CMakeLists.txt
1cmake_minimum_required(VERSION 3.5 FATAL_ERROR)
2
3project(cluster_extraction)
4
5find_package(PCL 1.2 REQUIRED)
6
7add_executable (cluster_extraction cluster_extraction.cpp)
8target_link_libraries (cluster_extraction ${PCL_LIBRARIES})
After you have made the executable, you can run it. Simply do:
$ ./cluster_extraction
You will see something similar to:
PointCloud before filtering has: 460400 data points.
PointCloud after filtering has: 41049 data points.
[SACSegmentation::initSACModel] Using a model of type: SACMODEL_PLANE
[SACSegmentation::initSAC] Using a method of type: SAC_RANSAC with a model threshold of 0.020000
[SACSegmentation::initSAC] Setting the maximum number of iterations to 100
PointCloud representing the planar component: 20522 data points.
[SACSegmentation::initSACModel] Using a model of type: SACMODEL_PLANE
[SACSegmentation::initSAC] Using a method of type: SAC_RANSAC with a model threshold of 0.020000
[SACSegmentation::initSAC] Setting the maximum number of iterations to 100
PointCloud representing the planar component: 12429 data points.
PointCloud representing the Cluster: 4883 data points.
PointCloud representing the Cluster: 1386 data points.
PointCloud representing the Cluster: 320 data points.
PointCloud representing the Cluster: 290 data points.
PointCloud representing the Cluster: 120 data points.
You can also look at your outputs cloud_cluster_0000.pcd, cloud_cluster_0001.pcd, cloud_cluster_0002.pcd, cloud_cluster_0003.pcd and cloud_cluster_0004.pcd:
$ ./pcl_viewer cloud_cluster_0000.pcd cloud_cluster_0001.pcd cloud_cluster_0002.pcd cloud_cluster_0003.pcd cloud_cluster_0004.pcd
You are now able to see the different clusters in one viewer. You should see something similar to this:
